How to start to Data Scraping for Beginners

I worked a lot with journalists (mostly non-tech people) to produce data journalism stories. The basic (or hardest problem) at the beginning of the journey is “how to get data” (aka) “how to scrape data” to be usable. This article is aimed for beginners who are interested in learning data scraping skills.
What’s Data Scraping & How to prep?
The simplest explanation is the process of extracting data from papers, pdf files or websites and transforming them into machine-readable data tables in Google Sheets or Excel.
Before you start data scraping, the first question you must ask is “Where will your data come from?”. Is it from a bunch of old newspapers? Is it from monthly PDF files that you need to download from the Government websites? Is it directly published on a website in table format? Based on such questions, you will get a list of sources that you’ve to do data scraping over them. Good practice is to write down these resources in a note or a spreadsheet that can be referenced in future uses.
General Types of Data Scraping
We can generally classify into two groups for your sources. One is PDF Scraping and another is Web Scraping. PDF Scraping is basically scraping data from offline sources (e.g: PDF files or Scanned documents or images). Web Scraping is scraping data from online sources (e.g: websites or APIs).
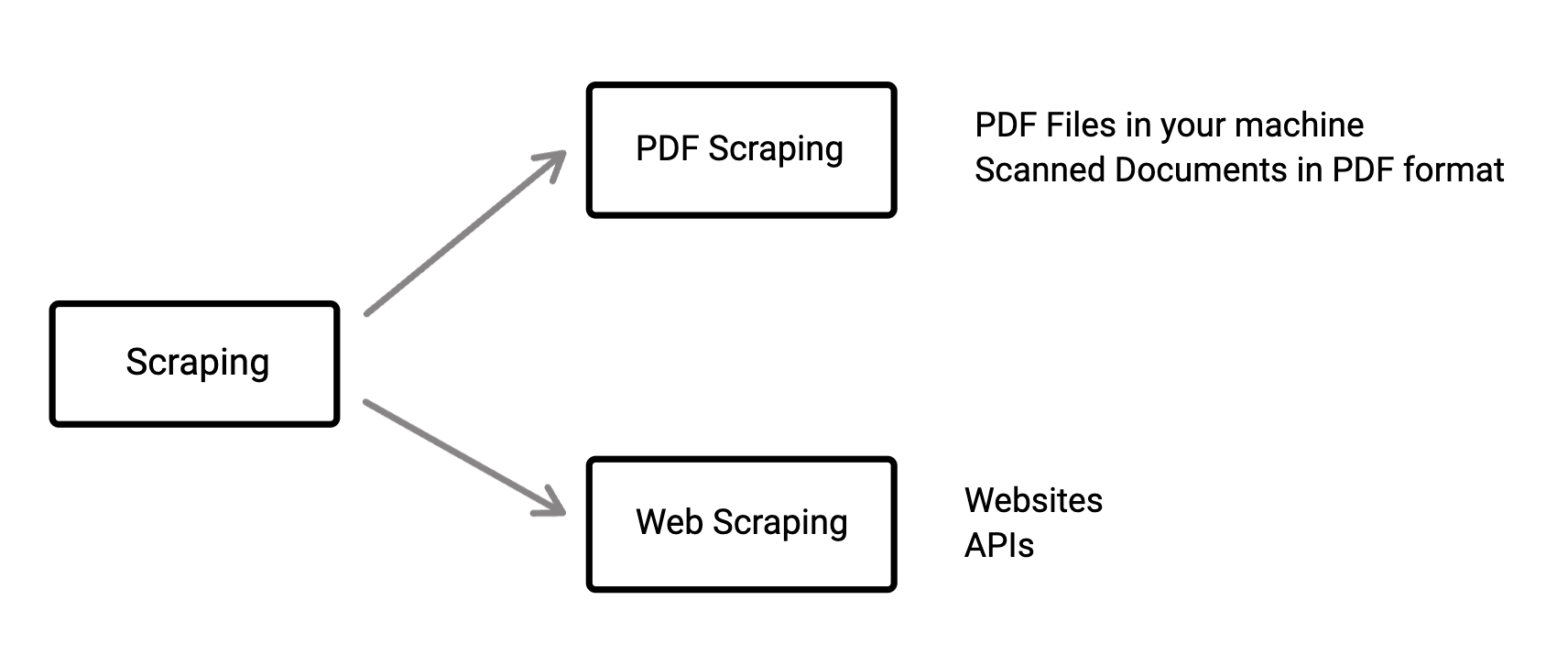
PDF Scraping
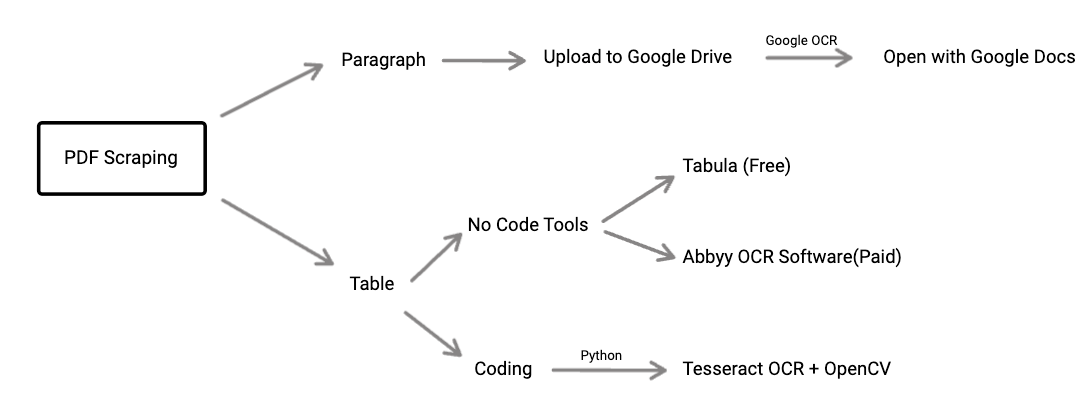
We can classify again to be more understandable. The data that you want to extract from PDFs might be text in paragraphs or text in table format. Depending on your needs , the PDF scraping methods will be varied.

Paragraph Scraping
Let’s start with paragraph scraping from your PDF. The easiest way is to use Google OCR for free. The first step is you have to upload the PDF file or image file that you would like to extract data into your Google Drive. (If you want to extract only a few pages of pdf , you’ve to split the PDF files by using applications - e.g: using online splitter. Or you can also convert pages from PDF into images - e.g: using online converter). Then , upload into Google Drive , right-click over the file (PDF or image), choose > open with Google Doc. Yay , you got the paragraph text inside the editable Google Document. This process can be painful if you’ve several pdfs or images to extract data , then you can use Google Apps Script to do Google OCR over multiple files automatically. Good tutorial here.
Table Scraping
Extracting tables from PDF files or images can be a little tricky than extracting paragraph. The first option is to use a free, open source tool like Tabula. You need to install Java , then install the Tabula application and can use it easily to scrape tables from PDF files. Even though Tabula was a powerful and useful tool, it had some weaknesses that it can't be used over images and it’s working well for English language data , but not for other languages. The other option is to use paid applications like Abbyy screenshot reader. It’s more powerful than Tabula and has more support in several languages but you need to pay for their services. If you’re an experienced developer that can use Programming Language, you can avoid the cost and pain points of no-code tools by trying Tesseract OCR + OpenCV for table data extraction.
Web Scraping
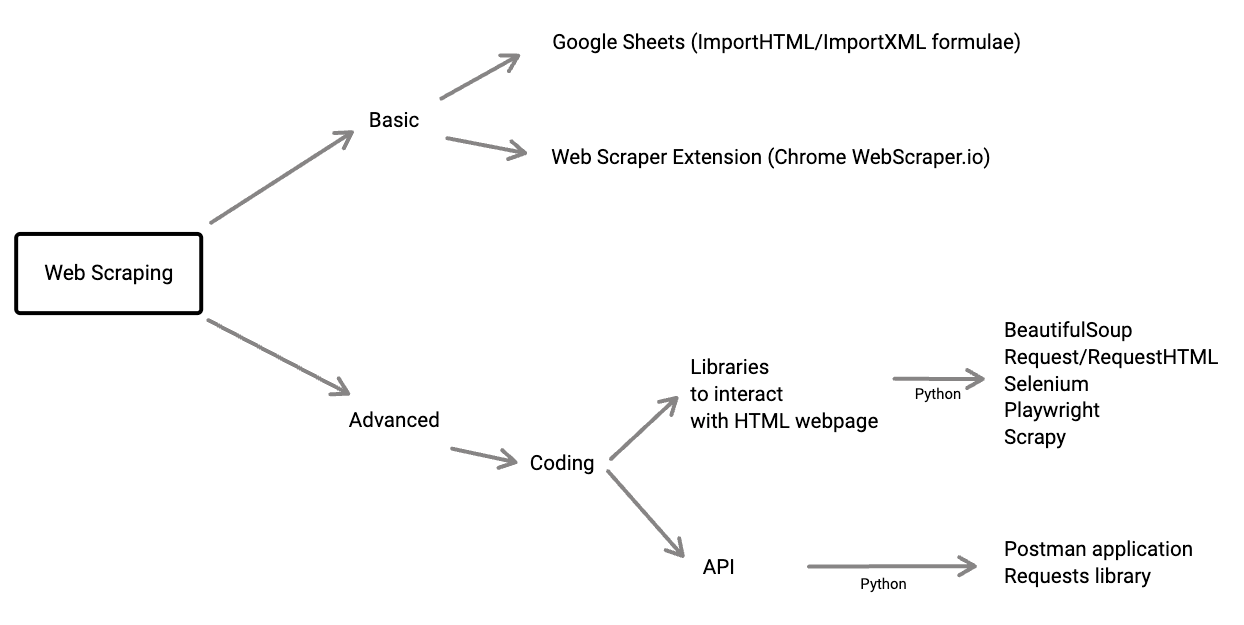
As its name suggests, it’s getting data from the web (that can be websites or web portals). To start working on web scraping , it’s better if you know HTML & CSS. Mozilla MDN web docs will be a good reference for you.
The basic and simplest thing to start web scraping is try to use IMPORTHTML from google spreadsheet. It can import tables or list data from the website. So, you’ve to make sure the data that you want from the website is in html table or html list format. Another easy way to try web scraping is using web scraping extensions on your browser (e.g: Webscraper.io). Most of these extensions are easy-to-use and based on click-&-select functionality , but it’ll be more easier & efficient if you’re already familiar with HTML,CSS.
Above techniques (Google Sheets formula or Browser extensions) have limitations if you want to do more interaction with web pages (e.g. select option from dropdown menu and scrape the results). These advanced steps can be implemented by using programming languages. If you’re able to use Python, there’re several libraries available for scraping purposes. Popular ones are BeautifulSoup, Scrapy, Requests-html, Selenium, Playwright. But sometimes, when you checked the webpage and their data is available to scrape from API, you might need to familiarize yourself with Postman application or Requests library.
In conclusion, I hope the methods or tools that I introduced above will be useful for the beginners to start working with data scraping.