MLOps isn’t DevOps for ML!
From Software 1.0 to Software 2.0: Harnessing DevOps for MLOps?
By aspiring to address each step from model creation through deployment, MLOps is asking too much. It creates a parallel development process that requires special resources and expertise that are in short supply today. On the flip side, there are mature processes and abundant talent in the established discipline of DevOps.
The fact is ML models are [...] familiar DevOps practices and tools actually work well. What we need are ways to fit ML models into the software world.
— thenewstack.io ; For AI to Succeed, MLOps Needs a Bridge to DevOps
It claimed that the big talent gap in the MLOps market can be easily and abundantly filled by DevOps practitioners in the conventional software world. After all, isn’t AI/ML just Software 2.0? Thus, MLOps is just DevOps for Software 2.0, right? If a=b and b=c then a=c: Jesus, a no-brainer. But if only!
Let’s talk about both one by one.
Machine Learning is not Software 2.0
Andrej Karparthy captured this idea of software 2.0 as the code that doesn’t require explicit programming, proposing that while it may likely remain unintuitive to the human given the homogeneous transposition using only weights and biases however it could potentially claim better performance along several metrics including agility, stack homogeneity, etc. While intuitively, a data-driven no-code code was easily software 2.0 however over the past few years it has only become more and more apparent that deploying these machine learning models in production towards the vision of “One Model To Learn Them All” presents its own challenges. 2017-19 were the years of bigger and bigger models, meta-meta-learning, and a constant struggle to pursue AutoML research toward being able to develop large generalizable models. However, with the widespread adoption of AI in any and every company with an engineering team and massive data at their disposal, things have shifted rapidly.
While in theory, a neural network should be likely to provide better predictions than classical machine learning models however in practice, that hasn’t always been the case. Over the past few years, there has been a keen awareness amongst data science practitioners that the bigger ensemble models and hyper-parameter optimization is mostly not the solution to all problems, and smaller well-understood, and domain-specific feature-engineered interpretable models are able to deliver acceptable levels of accuracy on most business problems. The toy problems in research fail to aptly capture the complexity of real-world engineering and business proposition to continue investing resources in the domain.
Machine learning models, as they are, require plenty of continuous human engineering at all stages from requirement engineering to data drafting to feature engineering to model deployment to observability and monitoring, given the data drift and unforeseen data samples that weren’t captured while training the model. This has created a massive debate in the machine learning community about how often we need to re-train our models in production as well as failsafe practices when something goes wrong. While clearly-defined immutable problems like detecting cats vs dogs can be far easily solved using neural networks however making even a preliminary medical diagnosis on patients in a single clinic requires humans in the loop.
Not only is there a gap between business understanding and predictive planning of the problem but also the need for massive amounts of data has brought up some very interesting questions around data contracts, governance, bias, interpretability, and ethics. There is no no-longer just one moving piece i.e. how many features/functions can we build into the software we ship but also the complexity introduced by variable data, and the constantly shifting business KPIs, different versioned models, and infrastructure code to deploy the same. And this is, after leaving out the challenges around the high veracity, velocity, and volume of the real-time data being captured by the minute that is now not just something to add to the database but an important feature to be immediately processed for the product in terms of recommendations and responses. This brings newer challenges around diverse data sources, data validation in pipelines, designing good data architectures, and best practices for maintaining, measuring and monitoring data ingestion, transformation, and orchestration pipelines.
Since 2018, we have seen a massive eco-system of tooling companies trying to bridge these “gaps” in trying to deploy these machine learning models on production collectively clubbed under the umbrella term “MLOps”.
The recent ML/AI eco-system report by Linux Foundation lists several tools, packages, and libraries however it barely manages to scratch the surface when it comes to the ground reality in November 2022 where a single V.C. Fund, Insight Partners has invested in 21 startups over a period of 20 months between 2021 to now in the data and analytics space and that’s only a general trend across VCs.

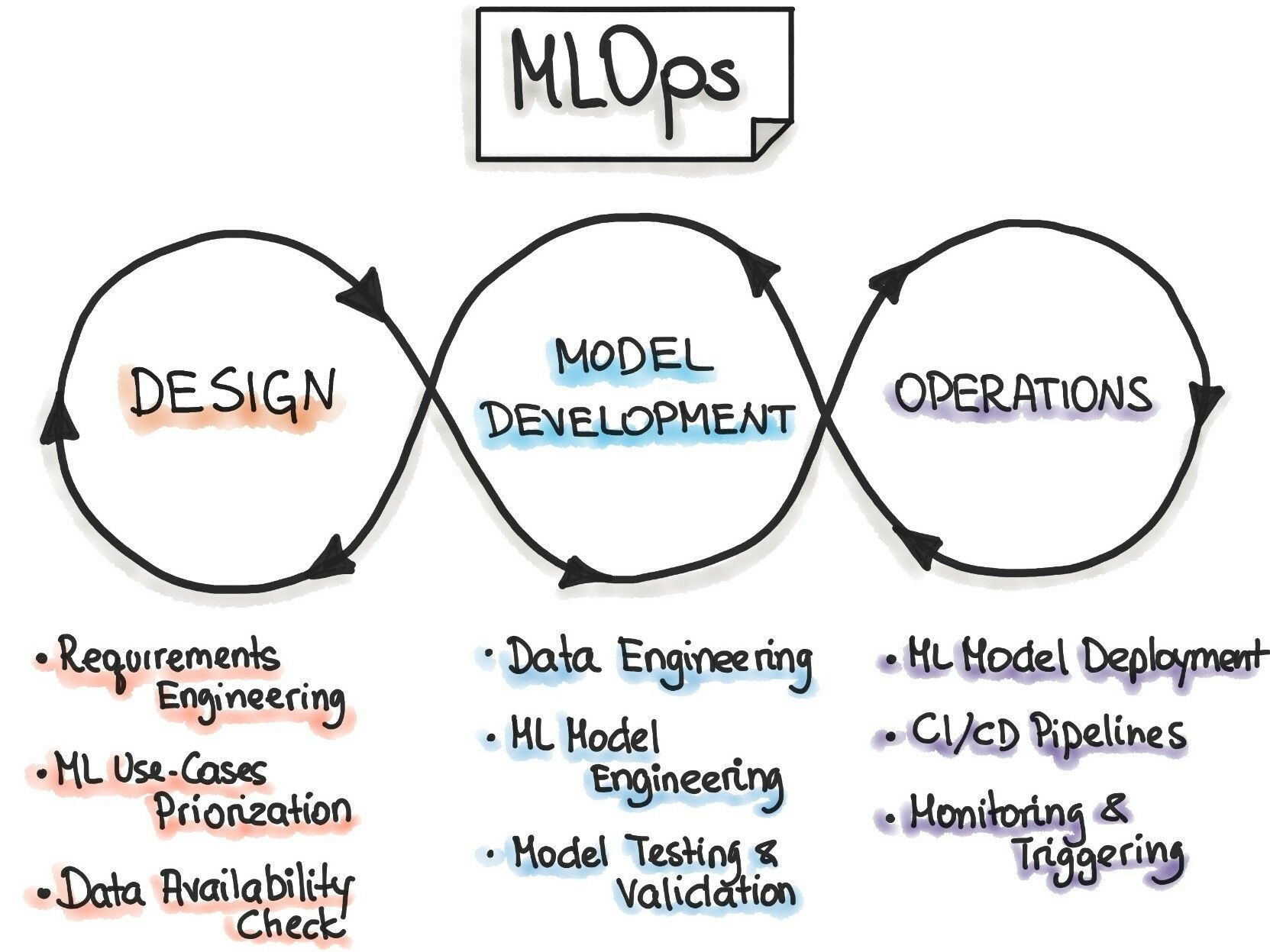
What is MLOps?
The definition of MLOps is as murky and personable as the definition of artificial intelligence itself. The simple answer is it depends on whom are you asking.
While most data science/machine learning practitioners tend to define MLOps as “the set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently”. This consists of a continual loop of
- data collection and labeling
- experimentation to improve ML performance
- evaluation throughout a multi-staged deployment process
- monitoring of performance drops introduction
The organizational gurus define it as “the set of practices for collaboration and communication between data scientists and operations professionals and that applying these practices increases the quality, simplifies the management process, and automates the deployment of Machine Learning and Deep Learning models in large-scale production environments thus aligning models with business needs, as well as regulatory requirements.”
The adoption of machine learning in software isn’t new. The spam detection and Inbox team at Google have been working in NLP for years now. The Google SRE teams have been leveraging and experimenting with MLOps since 2014. They have focussed on some critical pieces in MLOps engineering including the idea of creating a feedback loop in production, using continuous delivery and continuous integration, and using tools and services that are tailored to MLOps needs. They have also worked on scaling ML infrastructure, where they aim to minimize the similarity gap between the test and production environments. Additionally, they have also looked at making sure that the data collection processes are efficient, reliable, and control-compliant. However, investing in teams to build out these platforms that can be used internally at Google is possible at FAANGs or MANGA, however, it is still a roadblock at several smaller and non-vendor companies.
Over the past few years, the adoption of cloud engineering, understanding of big data, and open-source libraries for predictive modeling have made it easier for everyone to be enticed by the possibility to generate user insights or personalize their “software 1.0” by hiring a team of data scientists. However, to most companies’ constant surprise, data scientists alone have been far from adequately equipped to handle/guide the end-to-end deployment or monitor or debug these models once deployed in production. It truly needs an army, some in-house and some outsourced to the A.I. tooling/SaaS companies. While every data team at different companies is substantially different however there are some uniformity and core challenges that are common to everyone.
Core Challenges in MLOps
- For a machine learning model to be considered successful, it must be able to generate stakeholder buy-in. Thus, it becomes incredibly important to tie the models to business KPIs instead of the accuracy scores (F1, recall, precision, ROC, AUC). However, with business KPIs changing every so often through different stages it becomes incredibly hard to measure the model performances.
- For any business to build powerful and reliable ML models, investing effort into creating and maintaining a data catalog becomes crucial to track which data source is the model being trained on and track meta-data. However, the real challenge is building relevancy into data discovery. A lot of out-of-the-box commercial data cataloging solutions do not adapt to different organizations’ data needs and cost several kidneys and more. Building an in-house solution definitely requires upfront investment and a team with an excellent understanding of user-friendly database design practices thus making it an incredible time and resource-consuming process. To make it even harder, there is a lack of documentation around best practices about creating, managing, and scaling an in-house data-cataloging tool and evaluation metrics so as to not end up with an incomplete catalog esp with the new live data being streamed into the system making the effort futile at best.
- Your machine-learning model is only as good as your data. However, data quality and more importantly labeled data quantity becomes key defining factors. However, best practices on data evaluation about how to standardize and normalize new incoming data are still case-by-case considerations. Also, most training environments need to come pre-loaded with few checks and balances based on the different stages of model deployment. For example, for a model that is being tested for production, has a random seed been set on the model to make sure that the data is divided the same way every time the code is run?
- While there are many advantages to using commercial feature stores however they can also introduce inflexibility and also limit the customization of models and sometimes you simply don’t need them. This inspires many to go with open-source solutions and develop their own on top of say Feast or DVC. While batch features may be easier to maintain, real-time features are sometimes inescapable but introduce a lot of complexity into the system, especially around back-filling real-time data from streaming sources with data-sharing restrictions. This requires not only technical, privacy but also process controls that is often not talked about. Recently, there has been more discussion around Data Contracts however, they are not yet a commonly accepted practice across organizations.
- There is a lack of commonly well-defined best practices around creating model version control. Undefined/poorly defined prerequisites about when to push a model in production can create unnecessary bugs and introduce delays during monitoring and debugging.
- Code Reviews—how much time should be spent on code review in different stages especially given the model behaviour may not accurately represent live training data and how frequently should they happen? Different companies currently have different systems for it. While some prefer one-off deployment, others have more clustered deployment stages eg. test, dev, canary, staging, shadow, and A/B for business-critical pipelines with different review stages and guidelines. However, even the end-to-end tools do not have any in-built support for the same. It’s very much only institutional knowledge as of now as to what makes good quality production code.
- To use static validation sets or dynamic validation sets to more closely resemble live data and address localized shifts in data.
- Model registries vs changing only config files instead of the model. For the former, if model validation passes all checks, the model is usually passed to a Model Registry.
- Having clearly defined rule-based tests to make sure the model outputs are not incorrect while factoring in when is it okay to give incorrect outputs (for eg. shopping recommendations) vs to give no outputs (for eg. cancer prescriptions).
- Best practices around code quality and a need for similar deployment environments. While most data scientists prefer working with Jupyter NBs however the way code is usually written in NBs (copy-paste) instead of re-using functions, can introduce unnecessary bugs and introduce technical debt when the notebook owner leaves the team.
- While experiment tracking tools and dashboards have added quite some observability into the model runs a lack of contextual documentation of the changes is still majorly unexplored and is limited to the core developers.
- While sandbox tools to stress-test can be quite useful in some scenarios however in others for eg. recsys it may not generate any useful information whatsoever.
- The Goldilocks warnings about which alerts are critical and require quick stop-loss migrating quickly to a failsafe model (for eg. hate speech, racial or gender bias) and which ones are mere information to be factored in for the next model configuration phase.
Conclusion
Given the immense complexity and domain-specific understanding of different machine learning problems and applications, MLOps often requires a lot of moving variables across the business, data, code as well as model engineering at each phase of the machine learning lifecycle. DevOps practitioners can at best serve as auxiliary partners to brainstorm developing more transparency and processes in the MLOps world from their experience in the software engineering development lifecycle.
But domain expertise around ML tools and techniques for stakeholder collaboration, internally as well as externally, will continue to be critical for the success of a machine learning project in production pipelines at scale, thus the assumption that existing DevOps from Software 1.0 world can easily come in to fill the talent gaps and swipe their magic wands to fix all the processes is nothing if not a naive half-baked proposal at its very best.
In conclusion, deploying machine learning models in production for many organizations is still in a nascent stage, however, the need for a new set of optimized MLOps engineers who can curate new systems and processes that are thoughtfully curated for machine learning teams and workloads is critical to ensure that the data and models are compliant, reliable, performant, and maintainable at scale.