The go-to guide for how to work with data people

The hardest things when working in data are not writing complex pipelines, understanding mathematical model, designing new deep learning models, or building shiny dashboards.
It's dealing with stakeholders. The people who operate the company: product teams, marketing teams, supply teams, financial teams, C-levels, etc...
In any modern company nowadays, those services rely on data to take decisions. Hence the existence of data teams.
But it has been hard to collaborate in a productive and seamless way between the data teams and its stakeholders.
This small guide aims to provide some keys to understand those partnership troubles. It's more targeted for people outside of data teams—to help everyone grasp the ins and outs of data.
There is no secret sauce and the TL;DR; would probably be the easy one: invest in people.
Who are we?
Before diving in the potential solutions and find how we can streamline data teams and stakeholders goals together, let take a tour of what's a data team at a glance.
The deepest will of a data team is to provide insightful information to help taking better decisions. At all company levels.
This commitment can be organic when operating in small and mid-sized companies. Any data sources is like a gold mine that we rush to extract any valuable information. We rely on external services to retrieve data and "data analysts" are working most of the time within spreadsheets. There is no need for a complex information system to run custom data integrations, run deep analysis and build forecasts.
But all this fails when we talk of "big data".
A break on that buzzword: "big data". Personal computers are more and more powerful . They can handle large data files nowadays. Still, there are some times where even a simple computer can't support the volume of data we have. That's why we talk about "big data".
That paradigm—a consequence of an ever growing connected digitalized world—brings a whole new problem space. We talk about clusters of machines, databases, softwares, machine learning, etc...
The analysts are still doing the same job but with different tools and constraints. It's harder to find the good data, to understand it, to maintain it. Hence the need for specific roles: the data engineer and the data scientist.
But whatever the amount and the complexity of data, the commitment is the same: create value from data.
So, data teams are commonly filled by three positions: data analyst, data scientist, data engineer.
We have to be very nuanced when discussing about what all those roles do. There are many overlaps between them. Still we can draw a general picture emerging from the different personas skillsets.
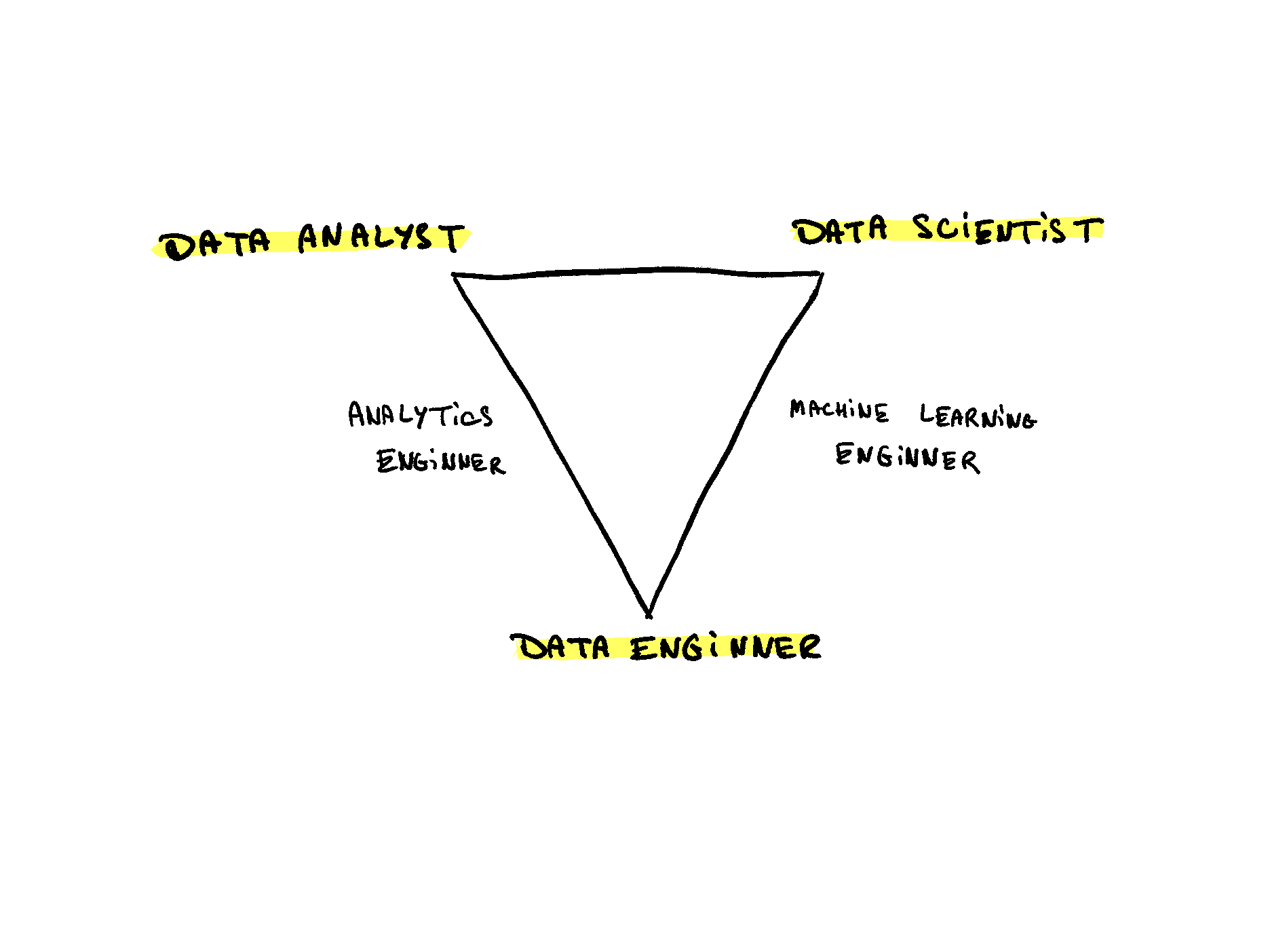
In a nutshell:
- Data Engineer: build pipelines to retrieve data from sources and gathering them to a place where they could be transformed by data-engineers themselves or other data roles.
- Data Scientist: build models to understand the data and predict future behaviours.
- Data Analyst: build analysis or dashboard to understand the data and answer business questions.
The analytics engineer is someone between the data engineer and the data analyst: he's here to build and maintain data models. Before the advent of this position, we had hard time to keep consistent data models ; we usually ended up with data duplicates, lack of governance, definitions discrepancies, etc.
The machine learning engineer job is to apply software engineering practices to deploy and maintain services supporting machine learning model training and predictions.
Finally, we could add a management layer to that triangle ; data managers, leads positions, and even product managers in some cases. Those ones are pretty basics and quite similar to any management role. We will discuss about them later...
That's being said, we can now look at why it's not that easy to create added-value from data. Why it take time and careful designs?
The Upstream Problem
Whatever the company, data are usually coming from different sources. Its customers, product referentials, sales, online website, offline stores, phone application, employees, etc.
In a utopia, a common protocol would create and handle these data. A similar contract. But that's not the reality.
Those data are moving in different systems, processed in different databases and used by different "consumers". This is not by intention but because companies are generally siloted across different business dimensions (sales, product, CRM, marketing, etc.) and so we adapted technologies to the nature of data.
For instance, storing and processing granular transactions is a different model than analyzing a huge amount of customer data across years and countries.
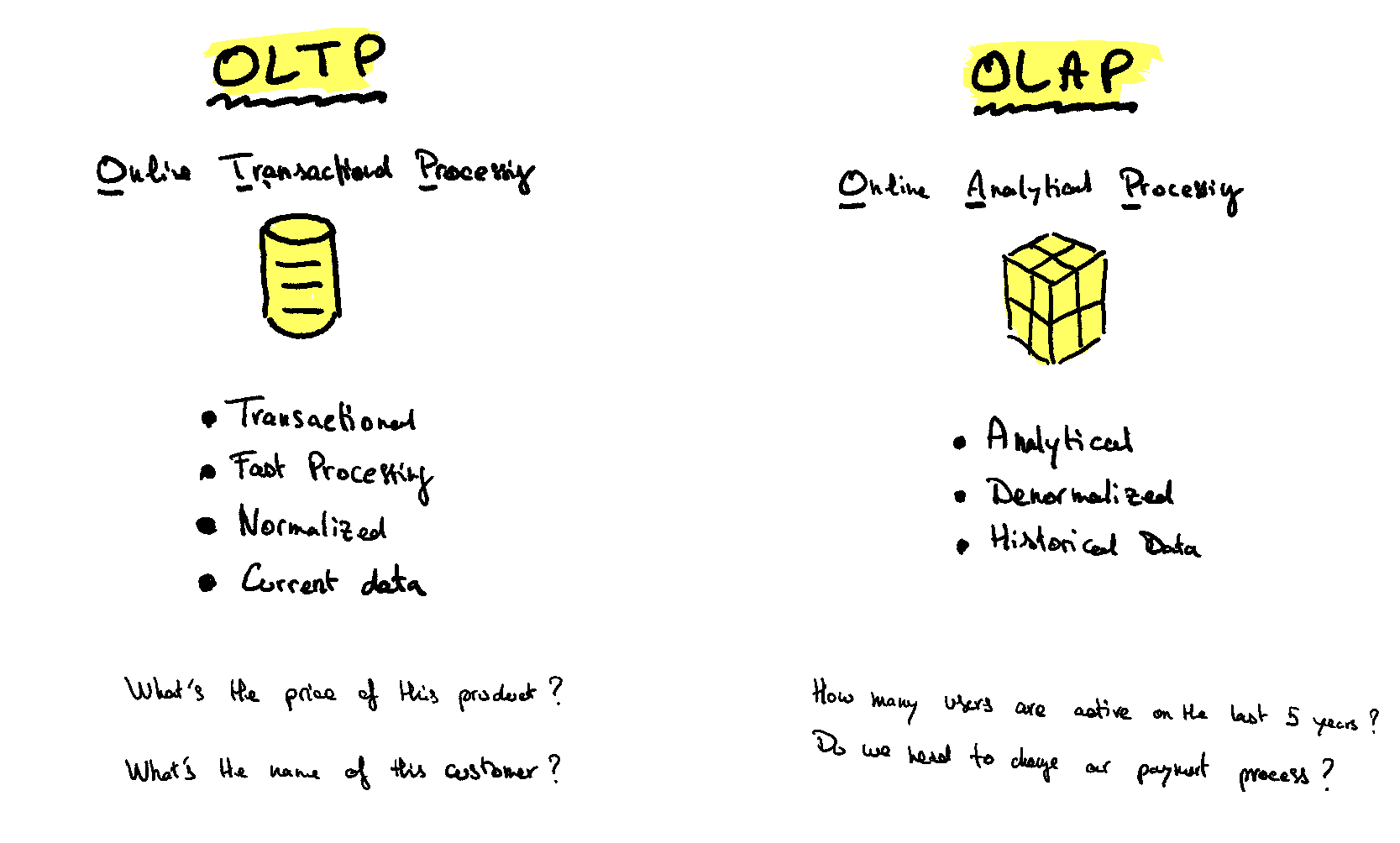
In our jargon we have the distinction between OLTP (Online Transaction Processing) and OLAP (Online Analytics Processing) systems.
— OLTP is basically every data recorded at user-level (sales, subscriptions, clicks on a website, etc..).
— OLAP is for data analysis, machine learning: where we need a vast amount of data with aggregation across many dimensions.
It's two different paradigms. So often distinct technologies.
So basically what a data team does is ingesting data from all these systems into one place (a "data lake") and processing them to be able to run analytics and build algorithms.
The main difficulty is easy to see: how to ingest and maintain all these different data in a reliable and consistent way?
Corollary, how to be sure that everyone understand data in the same way? A sale, viewed from a store and from the marketing team can have a different definition. That's essentially "data governance".
Finally, we can understand how hard it is to provide tidy and consistent data when the sources are many and often prompted by human error. That upstream problem is mostly a technology one. It's where data-engineering role is the most important.
The Downstream Problem
As companies are more and more data-driven, data is center piece of every decisions. Thus, data teams are accountable for many business stakeholders. Managing all the data demands is probably the hardest part of a data team. It's both a management and governance challenge.
Management, because you have to find the balance between business priority and team workload. Governance, because as it's now quite easy to provide any analysis or dashboard, it's way harder to manage the knowledge created from these assets. It's not rare to have two different dashboards with almost the same name but with huge data discrepancies...
The lifecycle of data is unsynchronized by design and so keeping a synced governance around it is a daily job. We try to automate as much as possible. To be able to provide insights at the same pace the company is running (hint: it's fast).
This downstream problem is directly due to the speed the business is running. We're accountable for too many business domains, each one coming with thousand of requests. Hence the discrepancies between data, dashboards, analysis, etc...
Data analysts are running on it while data engineers try to keep all that mess consistent, reliable and scalable. Managers get high pressure from their team to slowdown and from stakeholders to speedup delivery.
But even the best CEO wouldn't say "let's slowdown, so we can keep our decisions safe from inconsistency and unreliable data". It's actually the opposite: "let's recruit data people so we can deliver faster and better insights".
And so data teams are now made of many engineers and analysts. But we're new to this game. We often hear that data is 10 years late from software teams. That's true. Software teams are organized to handle many requests from many business stakeholders. They deliver fast, and craft reliable and scalable products.
We, as data teams, are on that path too.
A new paradigm - inspired by the dominant service oriented architecture (SOA) now in place in software - is making some noise recenlty: the data mesh. For more information you can read that blog post. Futur will tell if it's nothing that will fill the problem space with good solutions...
What you (should) can do?
So how do we address those two problems? Data is now at the center of the company and any new work need a data part.
As a marketer, a sale, a C-level, a software engineer, a product manager, there are several things you can do to improve the way data is handled in your company:
- Ask yourself if what's you're asking fits in the long term strategy. If it's something not really important, keep it in your backlog and seek for a project sponsor.
- Stop doing things on your own (alone). Without giving public access early. For example, editing a data extract in Excel spreadsheets. It's not a reliable process when you're the only one processing data. Even more when nobody from the data team heard about it. That's shadow data.
- Talk with data people. Crave for an horizontal relationship.
- Understand the system as a whole. If you're data are always late and falsy, it's often not data team's fault.
- Track your decisions. Do you use that dashboard you asked several weeks ago? Did you take a decision based on data recently? By tracking your moves you'll have power to ask for bigger projects. Moreover, the data team will love you.
- Seek for automation. We're living in codebases because writing code is way scalable than clicking in interfaces. No code tools have a cost: technical debt. Aims for low code tools or try software one time.
Data is not anymore a by-product of operation. It's operation. So instead of seeing it as a proper discipline, why not embracing it fully?
The business people, the actuaries, know what data they need and can define requirements, but typically don't have the skill set to design a data architecture that gives them the data they need. Technology people typically don't understand the business requirements, but they can design the data architectures. It's like the people in IT speak blue, the people in business speak red, but we need people who speak purple in order to create an appropriate solution"
🖇️ We the purple people
Data is not blue, is not red, but purple. It's upstream and downstream. It's everywhere. It's the best asset we have to access reality. So we need purple people. People that generate data and analyze it. We need you!
Thanks for reading! Don't hesitate to reach me at pimpaudben@gmail.com or on Twitter if you have any question.
If you liked this blog post, you should also look for further reading:
👉 We the purple people
👉 The difficult life of the data lead
👉 What's shadow IT?
I also have a newsletter you can subscribe to ✉️ From An Engineer Sight.