How to get Started with Data And Help Your Community

Turning the page on 2022, it's time to think of your New Year's Resolutions. For those of you who want to up your skills in Data Engineering, Machine Learning, and Data Analytics, why not build your skills on public sector datasets rather than on random Kaggle datasets? There is no shortage in this world of problems or data, but there is a shortage of professionals with an interest to evaluate them, especially in the public and non-profit sectors!
Let's pick an issue, like housing, and see what we can learn in the process.
Problem Statement
Ever since the Great Recession, corporations have been snapping up single-family homes across the US and are causing a housing crisis; especially in "post-industrial" cities like Cincinnati, Ohio. Laura Brunner, President of the Port of Cincinnati, said in testimony in front of Congress that the once privately held homes make "a cash cow for investors but a money pit for renters." Some have even leveraged technology to manage properties in dispersed geographies from afar with minimal staff, becoming what this author calls, the "automated landlord."
Since 2008, which neighborhoods have seen more single-family properties go from individual ownership to corporate ownership adjusting for size of neighborhoods?
Solution
There were roughly 60,000 transfers of single-family properties between 2008 and October, 2022, which I classified as going from a corporate entity to another corporate entity, corporate entity to person, person to corporate entity, or person to person. I took the difference of person -> corporate minus corporate -> person to calculate the net of how many of the properties went from individual ownership to corporate ownership. After geocoding and aggregating by neighborhood, I adjusted the raw counts for relative size of the neighborhood and found neighborhoods like Corryville, CUF, Avondale, and North Fairmount were the biggest targets for corporate ownership while neighborhoods like OTR and Pendleton went in the reverse direction.
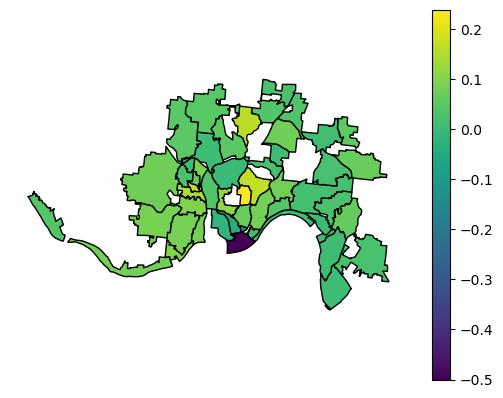
What skills were used in the process and what could you learn if you were to replicate this?
Data Engineering
Data Sources:
- Cincinnati Area Geographic Information System (CAGIS) Geodatabase
- Property Ownership Snapshots
- Property Transfer Information
- Property Use Code Mapping (Single Family are 510)
Skills to learn
- Batch Data Processing — Many organizations still process data in batches, whether snapshots or event processing (transfers). You could just process the snapshots at the beginning and end and see an increase/decrease in ownership, but the story could be in the transfers if there is a buying/selling frenzy. I used transfer counts in the visualizations above.
- Data Modeling (Normalization) — All of the files are flat files, which means you'll find a lot of redundancy. Where there is redundancy, there will be errors. Notice how "AUX FUNDING LLC" (the automated landlord from the Vice story) has the same owner address, but spelled differently. This can cause problems in data analyses depending on the problem you are trying to solve. Normalizing the owners by breaking them out into their own table will reduce those types of headaches.
- Data Modeling (Slowly Changing Dimensions) — Try creating a master ownership table utilizing type II SCDs with an effective_date field (when they acquired the property), an end_date field (when they gave up ownership), and a current_owner flag (boolean).
- Batch Data Pipeline — Transfer files are updated a couple times per month. Build a pipeline using Airflow that extracts from the website and upserts new data into your tables!
Machine Learning
Tools:
There is no flag to discern a human owner vs a corporate entity, so you have to figure it out on your own. ML can assist given there are tens of thousands of records to go.
Skills to Learn
- Tagging — This is a traditional Classification, so one way to go about it is to go through your data and tag it. I would recommend starting with a brute force SQL query to flag owners with words typically associated with US companies like '% LLC%', '% INC%', '% TRUST%', etc. You have to be careful with this approach or "SMITH V INC E" and "DI CORP IO LISA" will be listed as corporate entities.
- Modeling — Once you have a decent number tagged, pre-process the data. Models understand numbers and not strings, so you have to vectorize the data. The simplest and least compute would be to create a dimension for every word that appears with TF-IDF Vectorizer and then running your vectorized data through Scikit models.
- NER — Named Entity Recognition is a developed field in Natural Language Processing and you can find a lot of pre-trained models on Hugging Face to see if you can utilize this awesome resource.
Data Analytics
Sources/Tools:
Skills to Learn
- GIS — The CAGIS dataset at the top of the article has polygon coordinates for every single-family parcel in Cincinnati (filter by tax district: 1, class: 510). To get counts by neighborhood, join on the CAGIS index with geopandas.
- Statistics — After you have counts for the transfers by neighborhood, you'll find that a couple neighborhoods have a lot more than others. Is that an insight? Not necessarily. The City of Cincinnati paid a consultant tens of thousands of dollars to study the residential tax abatement program in Cincinnati and it also found that certain neighborhoods had high counts. What's wrong with just taking counts? The denominator. A neighborhood like Westwood (upwards of 6000 single family properties) can't be compared with Winton Hills (just under 100 single family properties) on a 1:1 basis, i.e. 400 transfers in Westwood's 6000 properties isn't as big of a deal as 400 in Winton Hills' 100 properties. If Westwood and Winton Hills were otherwise equal, you'd expect just based on size that out of 100 transfers, 98 of them would be in Westwood and only 2 in Winton Hills. The below visualization depicts counts only and paints a different picture.
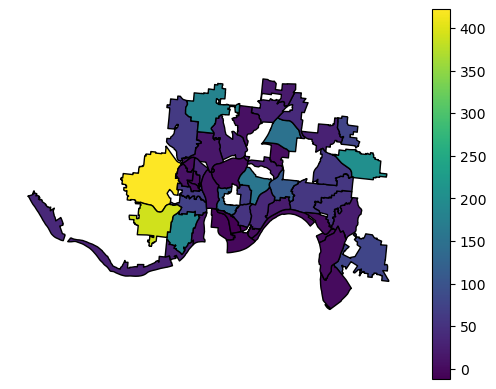
- Visualization — With Geopandas, you can use Matplotlib.pyplot, but give a different library a try like Plotly! Try different types of visualizations like heat maps in addition to the choropleth.
What's Next?
Give this a try or try it with similar data sources where you live. If the dataset isn't available, in the US, you can submit a Freedom Of Information Act (FOIA) request to obtain different datasets from the appropriate government organization. People often know there is a problem (e.g. with housing, with "food deserts", with lead exposure in children, etc), but oftentimes the analysis of the problem is either never really done or done expediently for some deadline. Communities need data experts like you to explore and define issues. You don't have to finish before you can start sharing your gained insights with your community. Only once leaders understand exactly where problems exist can they start to create a solution.
Plus, you can use the opportunity to improve your own data skills!